大家想必一定都有在購物網站輸入驗證碼的經驗,從早期的文字、語音、圖形與色彩辨識,到現在的一鍵選取"I am not a robot" ,但到底如何用勾選的方式,來澄清自己不是機器人呢? 難道機器人就不會自動勾選嘛?
下面是有一陣子Facebook在使用的人臉圖片驗證,來作為帳號二次驗證之機制,但相信很多擁有臉盲症的人都在裡面吃了不少苦頭,而前陣子很多驗證系統上,也套入了「請選出以下含有XXX的圖片」,相信大家都被這樣的機制用到好氣又好笑。

但這樣的驗證機制,不管是在購物網站還是一般的部落格Web的文章發布,甚至是留言功能,都是實屬必要的機制,而小編曾經在自己的產品上,因為遺漏了這樣的機制,造成被一群外星帳號瘋狂留言洗板,那各位一定不禁好奇這樣的驗證機制到底是怎麼演化來的呢?
最早的驗證碼機制不得不提到著名的電影大作,模仿遊戲裡面的電腦之父,也就是人工智慧的始祖艾倫圖靈,而接下來就是我們最常見Re-CAPTCHA公司,透過英文字元驗證碼,結合多彩的背景及光學扭曲的概念來進行驗證,而這間公司後來也被GOOGLE收購了,而當然這樣的機制最早也是利用在票卷販售系統身上,為的就是防止黃牛跟駭客進行大規模的攻擊和搶票作業,而中間我們常見的字體扭曲,也是為了避免有光學辨識的電腦去做自動判斷,CAPTCHA的原意如下:
C ompletely、A utomated、P ublic 、T uring test to tell、C omputers and、H umans 、A part
這時候相信有人不禁反問,那前面的Re-是什麼意思,是指重複利用的機制嘛?
其實並不是,這是當初發明驗證碼的團隊,想透過驗證碼的填寫所要進行的另外一像偉大計劃:讓全世界填寫驗證碼的人們,來協助紙本書籍的數位化

而數位化不外乎就是掃描以及光學辨識,但因為印刷以及掃描品質的關係,造成部分字彙無法透過電腦判讀,而這時候,偉大的使用者就派上用場了,當這些無法被順利辨讀的字彙被發現時,就會上傳到Re-CAPTCHA公司的資料庫,這時候產出的驗證碼就不在像過去那些無意義的四字母組成,而是變成一個具代表意義但不容易被辨讀的字彙,而透過使用者們輸入的大數據分析,就可以讓這些字彙被重新確認並回傳回電子書的資料庫。
而驗證碼又下方的「Stop Spam, Read Books」,也正是這項計劃的宣言,而也是這樣的契機,處成了Re-CAPTCHA公司被GOOGLE收購的引線,根據分析,每一年都將近有一億個字彙被辨讀,也促成了250萬本書的產出。
而這項技術背後看到的核心理念,其實相當簡單,目的都是要在15到30秒的現定時間內,去判定坐在螢幕前面輸入的這個傢伙,是人還是電腦,主要的核心將透過下面三個方向進行辨識:
1.固定型態的辨識:透過語言的邏輯,人腦可以在短時間內辨識出同一個字的變化,而這個數量可以高達無限,但是電腦卻需要透過資料庫的新增來有辦法做判讀。
2.分辨區隔:根據研究顯示,字母中間的順序以及間隔無法影響人腦對辨識的精準度,而這一點也是電腦無法比擬的
3.整個字的意義:同上,即使假使字母中間有些扭曲的字無法辨認,但因為我們對語言的邏輯去導讀整個字時,就會知道這個字怎麼拼。
4.加入扭曲的背景和圖像,增加辨識的難度,在透過上述三者的合成,這樣的難上加難,就可以使電腦無法有效還原這些辨識碼中寫的字串
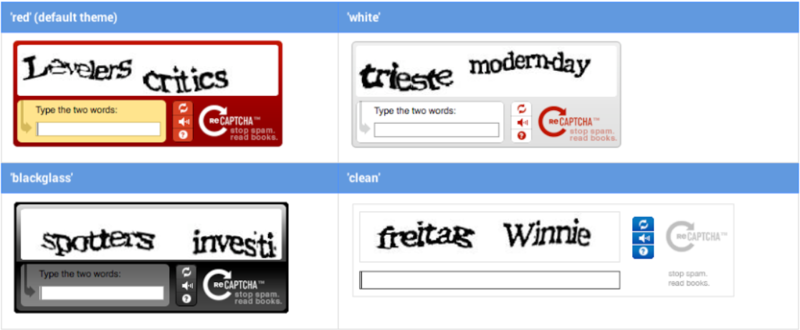
而這項計劃被GOOGLE收購後,更是擴展到影像拍攝及辨認上,當時GOOGLE力推想要將世界上的街道影像並且電子化,而透過驗證碼的方式,也可能讓民眾來辨讀那些被拍攝到,卻不易辨認的街道巷名,但可惜這樣的方式,仍然並未有效區分人類和機器人的行為,僅管再有意義,卻仍然需要和那些廣大的機器人程式去拼鬥
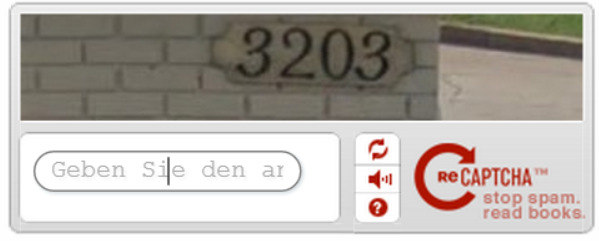
所以更衍生出了下面幾種的辨識碼
1.增加難度,並且新增語音補助幫助導讀
2.KCAPTCHA:把辨識的文字間隔縮到最小,讓所有的文字都「黏」在一起,讓電腦難以判讀。
3.動態CAPTCHA:讓字母移動提升電腦識別難度
4.標籤雲式的驗證碼
而中國的驗證碼就更有意思了,例如碼驗證碼換成圖片,或是利用廣告的方式來崁入驗證碼,或是用中文的成語來組成驗證
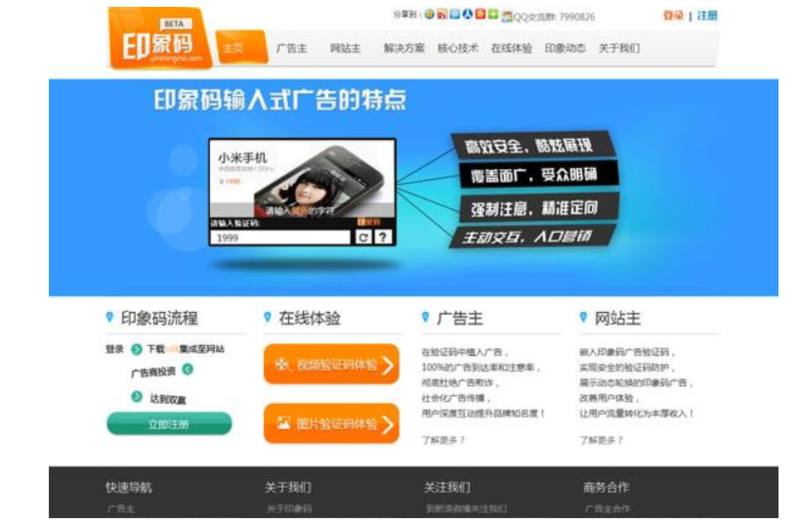
但相信眾多使用者一定有感,複雜的驗證碼不僅對UX來說是一種扣分,更是會讓使用者因為無法辨識而生77,盡管是為了機器人上去做的一層防禦,但所有的使用者都不覺得驗證碼是個受歡迎的東西,於是目前Google有的新的想法
noCAPTCHA reCAPTCHA:不需要輸CAPTCHA 的驗證碼
只需要點選CheckBox的「我不是機器人」,就會傳送勾選使用者的資料到 Google 的伺服器中,包含你勾選當時的 IP 位址、國家、時間,以及你打勾之前在該頁面(或是該網站的)的滑鼠軌跡、動作以及網頁瀏覽和捲動記錄。利用這樣的條件來判斷你是不是機器人,更大幅縮短了你輸入驗證碼的時間,這樣是不是很棒棒,而當你的動作無法判斷是否為人類時,開頭的圖片辨識就會派上用場,利用語意的導讀使你在圖片上去勾選正確的答案
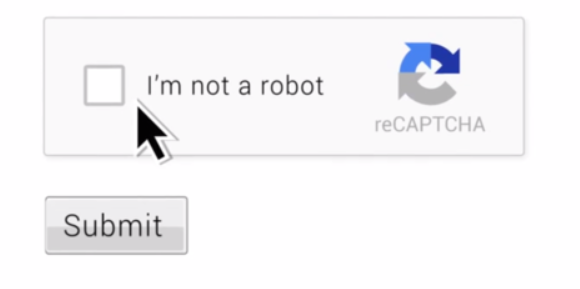
只是這一切都是來自於理想。
新創公司 Vicarious在2017年發表過一篇新聞稿表示,他們已運用 AI 開發出一種演算法模型,可以完美解答初驗證碼的機制,過去這種機器人AI多是採用深度學習(Deep learning)的方式,來訓練 AI 反應特定事物,透過這樣的訓練,AI 能逐漸學會辨識圖中不同字母,但一旦字母互相重疊或是扭曲,AI 便會難以辨識。Vicarious 團隊改採用遞歸皮質網路(RCN)技術,在訓練階段,AI 看到字母就會去建構出它所認知的字母模型概念,並試著理解、猜測字母的輪廓、內部、背景等。接著透過不斷新的圖片出現,AI 便會試著運用過去建立的理解,去揣摩人類對語言的推理和記憶行為來解釋圖片。當字母部分重疊、扭曲或是顛倒時,更可理解缺失是因為字母部分隱藏在另一個字母後面。

僅管開發機器學習的目的不是為了破解驗證碼(喂),但想必這場人腦與機器人AI的戰爭,現在仍未高下立判,接下來會怎樣發展呢?就讓我們拭目以待。

