大家還記得之前打敗世界棋王的 Google AlphaGo嗎,以及現在非常火紅的精準醫療和翻譯機器人嗎?近年來我們時常在報章媒體上聽到所謂的"人工智慧",都容易讓我們直接連想到電影情節,不管是「AI 人工智慧」或是「駭客任務」裡被機器人統治的場景,彷彿人工智慧的浪潮,正在我們對機器人的殷殷期盼下,席捲而來。在各大企業的2018目標裡,不管是 Google、Facebook、微軟或是百度等,我們也可以發現各巨頭紛紛也在人工智慧的領域裡充當領頭羊,擔任了研發擔當的角色,也在告訴我們人工智慧已經不再是憧憬,而是趨勢

但人工智慧是什麼呢?跟我們先前提到的機器學習有什麼不同。
首先我們必須從「智慧」這個名詞來做一點講究?假設我們現在跟自動聊天機器人來聊天,而他可以準確的回答我們的問題,例如下雨天他會提醒我們要帶傘,或是可以跟我們稍稍的打情罵俏,像Siri一樣,這樣的電腦可以稱做"人工智慧"嗎?以本質上來說,他真的擁有智慧了嗎?過去這是許多哲學家在討論的問題,於是美國哲學家約翰.瑟爾 (John Searle) 便提出了「強人工智慧」(Strong A.I.)和「弱人工智慧」(Weak A.I.) 的分類。
強人工智慧就像電影裡面描繪的場景,讓電腦或是機器人擁有自主判斷的能力外,更多了情感、個性、社交等等的自我人格意識,例如復仇者聯盟的幻視,就是一個超強人工智慧的例子;而弱人工智慧就是可以模擬人類的行為做出判斷和決策。但過去因為受限於資料量、運算能力還有儲存空間不足的問題,所以強人工智慧一值無法順利發展起來,但由於近15年來因為硬體儲存成本的下降、加上運算能力增強及擴充,以及擁有大量的數據能做處理,才讓屬於若人工智慧的"機器學習"可以興起。

資料來源:http://www.ibtimes.co.uk/captain-america-civil-war-paul-bettanys-vision-will-be-all-about-allegiance-next-marvel-1528980
機器學習主要的用途同上一篇介紹到的,利用大數據來訓練"機器"可以對事件的判斷做出"預測",所以會有五大要素
1.獲取數據:機器學習必須先收集大量的數據來對機器進行訓練。
2.分析數據:找出數據的關聯性,也就是變數,例如降雨和濕度。
3.建立模型:透過數據的關聯性做出模型,有點類似人腦的經驗,例如降雨之後濕度會上升。
4.預測未來:為來可將新的數據輸入模型後,就可以得到補助決策,例如明天降雨,那智慧家電會直接開除濕機。
5.修正預測:透過不斷增生的新數據來修正模型內的參數
簡單來說,從大量的數據資料裡,結合統計模型來對未來事件做出預測,正式目前機器學習領域裡,重要的發展方向,舉凡像是Gmail的自動過濾垃圾郵件、Who's Call的自動過濾騷擾電話等等,這些都已經反應到"弱人工智慧"在我們現在的社會裡,的確是可實現的。

但除了機器學習之外,想必最近大家還聽過一個名詞叫做"深度學習"吧,那他又是什麼呢
假如機器學習是人工智慧的其中一個分歧,那深度學習也可以說是機器學習中的一條支線了。像是大家熟悉的AlphaGo,正式用這樣的方式來發展人工智慧。
早期機器學習的領域中有一條分支叫做"類神經網路"。就像大腦可以擁有需多神經一樣,去做不同的樹狀分支,而人工神經就是利用這樣的思維來做思考,你可以想像把一張圖切成碎片,並輸入到神經網路的第一層,接下來第一層的獨立神經原做出導讀與判斷後接續傳遞到第二層、以此類推到最後一層來產出結果,而其中每一層的判斷都會有一個權重來評估決策,並透過權重的總值來產出結果,後來這也被稱做為現在家喻戶曉的「深度學習」。

舉例來說,像雅量裡面提到的,假設我們今天拿到了一張圖去做類神經分析,那他會去拆解裡面所有的圖像特徵,並用神經元來確認每一個形狀、字母、符號、尺寸等等,透過權重跟高度訓練的推測,可以讓系統有87分得把握來推斷他是一張稿紙、剩下13分的機率來推測他是一塊綠豆糕,最後透過網路把正確的結果回傳給神經網路做修正。
當然過程中會出現大量的錯誤答案,但這也是一個絕佳的訓練機會,透過成千上萬,數以百萬計的圖像去做校正,來校正每一個神經元的輸入權重,不斷的滾動來取得精準的正確答案,讓圖片僅管颳風下雨、打雷起霧、或是馬賽克等等,都可以明確的辨認圖片裡的綠色物體,到底是稿紙還是綠豆糕。
其中最有名的就是2012年,吳恩達在 Google 所製作的貓圖測試,他在研究上的突破在於從根本上使用這些神經網路,增加了層數和神經元的數量,使神經系統變得更龐大,然後通過系統運行海量數據來訓練,據說他可是使用了一千萬支 YouTube 的影片圖像,將資料的「深度」也一並運用在深度學習裡,來取得更精準的答案,讓系統可以透過自行判斷來評判這張圖到底是不是貓,據說準確度可是已經超越了人眼的判斷了。

當然這些硬用上除了在判斷是不是貓咪之外,還有一些實質上的應用,例如磁共振成像掃描中的腫瘤指標,來確認影像內的物體到底是不是腫瘤,或是Google 的 AlphaGo 學習圍棋遊戲遊戲,並且反覆跟自己比賽來調整神經網路的比重,訓練它進行圍棋比賽,讓每一步棋下得更為精準,這些都是實際上深度學習的應用。
僅管現在把這樣的理論可以輕描淡寫的敘述,但在資源較匱乏的過去十年前,不論是硬體或是資源上,都無法去做這樣大量的計算資料,其中一個主因是因為大家都習慣把計算丟給電腦的CPU去做處理,但這樣透過加權分析的複雜計算,會用到大量的矩陣,而顯卡中的GPU才是最適合大量處理矩陣運算的硬體,但過去GPU不像CPU擁有編譯器 (Compiler) 這樣的設計。
而突破性的發展就是NVIDIA 在 2006 – 2007 年間推出全新運算架構 CUDA,讓使用者可以撰寫 C 語言、再透過 CUDA 底層架構轉譯成 GPU 看得懂的語言。這不僅讓NVIDIA身價水漲船高,也成為了現在深度學習運算中必用硬體的關鍵。
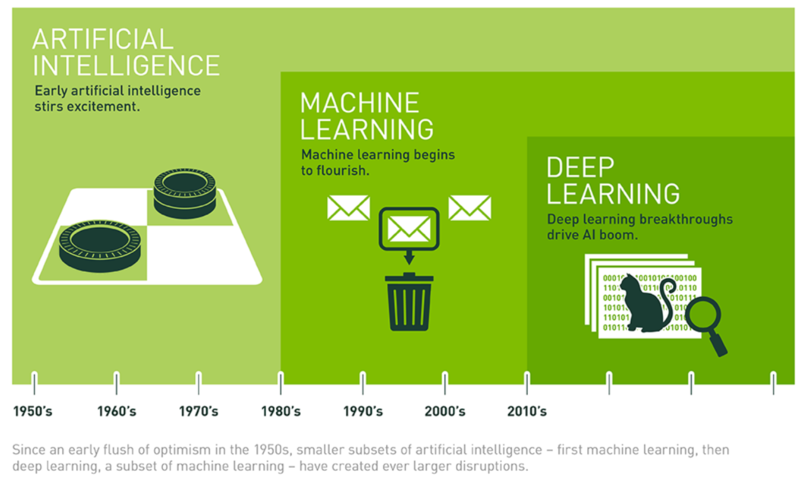
資料來源:https://blogs.nvidia.com.tw/2016/07/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
所以別再講人工智慧啦,先搞懂機器學習和深度學習的奧妙之後,才發現現在我們生活中,其實已經充滿了不少人工智慧在做生活上的支援決策囉,也許在不久的將來裡,強人工智慧的發展已經指日可待了。

